from zipimport import alt_path_sep
import pandas as pd
import numpy as np
from sklearn.utils.validation import check_is_fitted
from tensorboard.plugins.histogram.summary import histogram
housing = pd.read_csv('housing.csv')
housing.head()
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -122.23 | 37.88 | 41.0 | 880.0 | 129.0 | 322.0 | 126.0 | 8.3252 | 452600.0 | NEAR BAY |
| 1 | -122.22 | 37.86 | 21.0 | 7099.0 | 1106.0 | 2401.0 | 1138.0 | 8.3014 | 358500.0 | NEAR BAY |
| 2 | -122.24 | 37.85 | 52.0 | 1467.0 | 190.0 | 496.0 | 177.0 | 7.2574 | 352100.0 | NEAR BAY |
| 3 | -122.25 | 37.85 | 52.0 | 1274.0 | 235.0 | 558.0 | 219.0 | 5.6431 | 341300.0 | NEAR BAY |
| 4 | -122.25 | 37.85 | 52.0 | 1627.0 | 280.0 | 565.0 | 259.0 | 3.8462 | 342200.0 | NEAR BAY |
housing.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 20640 entries, 0 to 20639 Data columns (total 10 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 longitude 20640 non-null float64 1 latitude 20640 non-null float64 2 housing_median_age 20640 non-null float64 3 total_rooms 20640 non-null float64 4 total_bedrooms 20433 non-null float64 5 population 20640 non-null float64 6 households 20640 non-null float64 7 median_income 20640 non-null float64 8 median_house_value 20640 non-null float64 9 ocean_proximity 20640 non-null object dtypes: float64(9), object(1) memory usage: 1.6+ MB
total_rooms만 20433의 특성을 가지고 있다. 이 뜻은 207개의 구역은 이 특성을 가지고 있지 않다는 뜻이다.
housing['ocean_proximity'].value_counts()
ocean_proximity <1H OCEAN 9136 INLAND 6551 NEAR OCEAN 2658 NEAR BAY 2290 ISLAND 5 Name: count, dtype: int64
housing.describe()
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | |
|---|---|---|---|---|---|---|---|---|---|
| count | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20433.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 |
| mean | -119.569704 | 35.631861 | 28.639486 | 2635.763081 | 537.870553 | 1425.476744 | 499.539680 | 3.870671 | 206855.816909 |
| std | 2.003532 | 2.135952 | 12.585558 | 2181.615252 | 421.385070 | 1132.462122 | 382.329753 | 1.899822 | 115395.615874 |
| min | -124.350000 | 32.540000 | 1.000000 | 2.000000 | 1.000000 | 3.000000 | 1.000000 | 0.499900 | 14999.000000 |
| 25% | -121.800000 | 33.930000 | 18.000000 | 1447.750000 | 296.000000 | 787.000000 | 280.000000 | 2.563400 | 119600.000000 |
| 50% | -118.490000 | 34.260000 | 29.000000 | 2127.000000 | 435.000000 | 1166.000000 | 409.000000 | 3.534800 | 179700.000000 |
| 75% | -118.010000 | 37.710000 | 37.000000 | 3148.000000 | 647.000000 | 1725.000000 | 605.000000 | 4.743250 | 264725.000000 |
| max | -114.310000 | 41.950000 | 52.000000 | 39320.000000 | 6445.000000 | 35682.000000 | 6082.000000 | 15.000100 | 500001.000000 |
std행은 표준 편차를 나타낸다
25%, 50%, 75%는 백분위수를 나타낸다.
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(12, 8))
plt.show()

from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
housing["income_cat"] = pd.cut(housing["median_income"], bins=[0., 1.5, 3.0, 4.5, 6., np.inf], labels=[1, 2, 3, 4, 5])
5개를 가진 소득 카테고리 특성을 만든다.
예를들어 카테고리 1은 0~1.5($15,00 이하) 이다.
housing["income_cat"].value_counts().sort_index().plot.bar(rot=0, grid=True)
plt.xlabel("Income category")
plt.ylabel("Number of zones")
plt.show()

from sklearn.model_selection import StratifiedShuffleSplit
splitter = StratifiedShuffleSplit(n_splits=10, test_size=0.2, random_state=42)
strat_splits = []
for train_index, test_index in splitter.split(housing, housing["income_cat"]):
strat_train_set_n = housing.iloc[train_index]
strat_test_set_n = housing.iloc[test_index]
strat_splits.append([strat_train_set_n, strat_test_set_n])
split() 메서드는 훈련과 테스트 데이터 자체가 아니라 인덱스 를 반환한다.
여러 개로 분할하면 모델의 성능을 더 잘 추정할 수 있다.
n_splits = 10이라는 뜻은 10개의 계층으로 분할한다는 뜻이다.
하나의 분할이 필요하다면 간편하게 만들 수 있다.
strat_train_set, strat_test_set = train_test_split(housing, test_size=0.2, random_state=42, stratify=housing["income_cat"])
strat_test_set["income_cat"].value_counts() / len(strat_test_set)
income_cat 3 0.350533 2 0.318798 4 0.176357 5 0.114341 1 0.039971 Name: count, dtype: float64
for set_ in (strat_train_set, strat_test_set):
set_.drop("income_cat", axis=1, inplace=True)
housing = strat_train_set.copy()
housing.plot(kind="scatter", x="longitude", y="latitude", grid=True)
plt.xlabel("longitude")
plt.ylabel("latitude")
plt.show()

캘리포니아 지역을 잘 나타내지만 특별한 패턴을 찾기 힘들다. alpha 옵션을 0.2 주면 데이터 포인트가 밀집된 영역을 잘 보여준다.
housing.plot(kind="scatter", x="longitude", y="latitude", grid=True, alpha=0.2)
plt.xlabel("longitude")
plt.ylabel("latitude")
plt.show()

원의 반지름은 구역의 인구를 나타내고(매개변수 s)
색상은 가격을 나타낸다(매개변수 c)
여기서 미리 정의된 컬러 맵 중 파란색(낮은 가격) -> 빨간색(높은 가격)까지 범위를 가지는 jet을 사용한다.(매개변수 cmap)
housing.plot(kind="scatter", x="longitude", y="latitude", grid=True, s=housing["population"] / 100, label="population", c="median_house_value", cmap="jet", colorbar=True, legend=True, figsize=(10, 7))
cax = plt.gcf().get_axes()[1]
cax.set_ylabel("median_house_value")
plt.xlabel("longitude")
plt.ylabel("latitude")
plt.show()

주택 가격은 지역 및 인구 밀도와 관련성이 높은걸 알 수 있다.
군집을 찾고 군집의 중심까지의 거리를 재는 특성을 추가할 수 있다.
dataset이 너무 크지 않으므로 모든 특성 간의 standard correlation coefficient(표준 상관계수) 를 이용해 쉽게 계산 가능하다.¶
표준 상관 계수¶
상관계수 산정 방식에는 피어슨 상관계수, 켄달-타우 상관계수, 스피어먼 상관계수 를 사용한다.
- 피어슨 상관계수 : 코시-슈바르츠 부등식에 의해 +1 ~ -1 사이의 값을 가진다. +1인 경우 양의 선형 관계, -1인 경우 음의 상관 관계, 0의 경우 상관관계를 갖지 않는다.
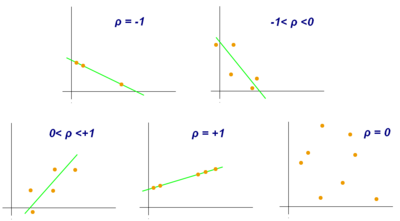 출처 : https://wikidocs.net/157461
* 켄달-타우상관계수 : 두 변수들간의 순위를 비교해서 연관성을 계산하는 방법이다.
* 스피어먼 상관계수 : 두 변수의 순위 값 사이의 피어슨 상관 계수와 같다.
출처 : https://wikidocs.net/157461
* 켄달-타우상관계수 : 두 변수들간의 순위를 비교해서 연관성을 계산하는 방법이다.
* 스피어먼 상관계수 : 두 변수의 순위 값 사이의 피어슨 상관 계수와 같다.
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.corr.html
corr_matrix = housing.corr(numeric_only=True)
numeric_only = True인 경우 숫자, 소수 bool 값이 있는 열에대해서만 연산을 수행한다.
corr_matrix["median_house_value"].sort_values(ascending=False)
median_house_value 1.000000 median_income 0.687151 total_rooms 0.135140 housing_median_age 0.114146 households 0.064590 total_bedrooms 0.047781 population -0.026882 longitude -0.047466 latitude -0.142673 Name: median_house_value, dtype: float64
median_house_value는 median_income이 올라갈 때 증가하는 경향이 있다.
latitude와 중간 주택 가격 사이에는 약한 음의 상관관계가 보인다.(즉, 북쪽으로 갈 수록 주택 가격이 조금씩 내려가는 경향이 있다.)
from pandas.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms", "housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8))
plt.show()

산점도 행령을 보면 중간 주택 가격(median_house_value)을 예측하는 데 중간소득(median_income)이 가장 유용해 보인다.
housing.plot(kind="scatter", x="median_income", y="median_house_value", grid=True, alpha=0.1)
plt.xlabel("Median Income")
plt.ylabel("Median House Value")
plt.show()

housing = strat_train_set.drop("median_house_value", axis=1)
housing_labels = strat_train_set["median_house_value"].copy()
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
housing_num = housing.select_dtypes(include=[np.number])
imputer.fit(housing_num)
SimpleImputer(strategy='median')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SimpleImputer(strategy='median')
X = imputer.transform(housing_num)
housing_cat = housing[["ocean_proximity"]]
housing_cat.head(8)
| ocean_proximity | |
|---|---|
| 12655 | INLAND |
| 15502 | NEAR OCEAN |
| 2908 | INLAND |
| 14053 | NEAR OCEAN |
| 20496 | <1H OCEAN |
| 1481 | NEAR BAY |
| 18125 | <1H OCEAN |
| 5830 | <1H OCEAN |
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder()
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat)
housing_cat_encoded
array([[1.],
[4.],
[1.],
...,
[0.],
[0.],
[1.]])
cateogories_ 인스턴스 변수를 사용해 카테고리 리스트를 얻을 수 있다.
범주형 특성마다 ID 카테고리 배열을 담은 리스트가 반환된다.
ordinal_encoder.categories_
[array(['<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', 'NEAR OCEAN'],
dtype=object)]
카테고리가 '<1H OCEAN'일 때 한 특성이 1이고(그 외 특성은 0), 카테고리가 'INLAND'일 때 다른 한 특성이 1이 되는 식이다.
한 특성만 1이고(핫) 나머지는 0이므로 이를 원-핫 인코딩 이라고 부른다.
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
housing_cat_1hot
<Compressed Sparse Row sparse matrix of dtype 'float64' with 16512 stored elements and shape (16512, 5)>
min-max 정규화¶
각 특성에 대해서 0~1 범위에 들도록 값을 이동하고 스케일을 조정한다.
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler(feature_range=(-1, 1))
housing_num_min_max_scaled = min_max_scaler.fit_transform(housing_num)
표준화¶
평균을 뺸 후 표준 편차로 나눈다.
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
housing_num_std_scaled = std_scaler.fit_transform(housing_num)
변환 파이프라인¶
from sklearn.pipeline import Pipeline
num_pipeline = Pipeline([
("imputer", SimpleImputer(strategy="median")),
("standardize", StandardScaler()),
])
num_pipeline
Pipeline(steps=[('imputer', SimpleImputer(strategy='median')),
('standardize', StandardScaler())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('imputer', SimpleImputer(strategy='median')),
('standardize', StandardScaler())])SimpleImputer(strategy='median')
StandardScaler()
housing_num_prepared = num_pipeline.fit_transform(housing_num)
housing_num_prepared[:2].round(2)
array([[-0.94, 1.35, 0.03, 0.58, 0.64, 0.73, 0.56, -0.89],
[ 1.17, -1.19, -1.72, 1.26, 0.78, 0.53, 0.72, 1.29]])
from sklearn.metrics.pairwise import rbf_kernel
from sklearn.cluster import KMeans
from sklearn.base import BaseEstimator, TransformerMixin
class ClusterSimilarity(BaseEstimator, TransformerMixin):
def __init__(self, n_clusters=10, gamma=1.0, random_state=None):
self.n_clusters = n_clusters
self.gamma = gamma
self.random_state = random_state
def fit(self, X, y=None, sample_weight=None):
# 사이킷런 1.2버전에서 최상의 결과를 찾기 위해 반복하는 횟수를 지정하는 `n_init` 매개변수 값에 `'auto'`가 추가되었습니다.
# `n_init='auto'`로 지정하면 초기화 방법을 지정하는 `init='random'`일 때 10, `init='k-means++'`일 때 1이 됩니다.
# 사이킷런 1.4버전에서 `n_init`의 기본값이 10에서 `'auto'`로 바뀝니다. 경고를 피하기 위해 `n_init=10`으로 지정합니다.
self.kmeans_ = KMeans(self.n_clusters, n_init=10, random_state=self.random_state)
self.kmeans_.fit(X, sample_weight=sample_weight)
return self # 항상 self를 반환합니다!
def transform(self, X):
return rbf_kernel(X, self.kmeans_.cluster_centers_, gamma=self.gamma)
def get_feature_names_out(self, names=None):
return [f"클러스터 {i} 유사도" for i in range(self.n_clusters)]
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import FunctionTransformer
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_selector
num_attribs = ["longitude", "latitude", "housing_median_age", "total_rooms",
"total_bedrooms", "population", "households", "median_income"]
cat_attribs = ["ocean_proximity"]
cat_pipeline = make_pipeline(
SimpleImputer(strategy="most_frequent"),
OneHotEncoder(handle_unknown="ignore"))
preprocessing = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", cat_pipeline, cat_attribs),
])
def column_ratio(X):
return X[:, [0]] / X[:, [1]]
def ratio_name(function_transformer, feature_names_in):
return ["ratio"] # get_feature_names_out에 사용
def ratio_pipeline():
return make_pipeline(
SimpleImputer(strategy="median"),
FunctionTransformer(column_ratio, feature_names_out=ratio_name),
StandardScaler())
log_pipeline = make_pipeline(
SimpleImputer(strategy="median"),
FunctionTransformer(np.log, feature_names_out="one-to-one"),
StandardScaler())
cluster_simil = ClusterSimilarity(n_clusters=10, gamma=1., random_state=42)
default_num_pipeline = make_pipeline(SimpleImputer(strategy="median"),
StandardScaler())
preprocessing = ColumnTransformer([
("bedrooms", ratio_pipeline(), ["total_bedrooms", "total_rooms"]),
("rooms_per_house", ratio_pipeline(), ["total_rooms", "households"]),
("people_per_house", ratio_pipeline(), ["population", "households"]),
("log", log_pipeline, ["total_bedrooms", "total_rooms", "population",
"households", "median_income"]),
("geo", cluster_simil, ["latitude", "longitude"]),
("cat", cat_pipeline, make_column_selector(dtype_include=object)),
],
remainder=default_num_pipeline) # 남은 특성: housing_median_age
housing_prepared = preprocessing.fit_transform(housing)
housing_prepared.shape
(16512, 24)
preprocessing.get_feature_names_out()
array(['bedrooms__ratio', 'rooms_per_house__ratio',
'people_per_house__ratio', 'log__total_bedrooms',
'log__total_rooms', 'log__population', 'log__households',
'log__median_income', 'geo__클러스터 0 유사도', 'geo__클러스터 1 유사도',
'geo__클러스터 2 유사도', 'geo__클러스터 3 유사도', 'geo__클러스터 4 유사도',
'geo__클러스터 5 유사도', 'geo__클러스터 6 유사도', 'geo__클러스터 7 유사도',
'geo__클러스터 8 유사도', 'geo__클러스터 9 유사도',
'cat__ocean_proximity_<1H OCEAN', 'cat__ocean_proximity_INLAND',
'cat__ocean_proximity_ISLAND', 'cat__ocean_proximity_NEAR BAY',
'cat__ocean_proximity_NEAR OCEAN', 'remainder__housing_median_age'],
dtype=object)
from sklearn.linear_model import LinearRegression
lin_reg = make_pipeline(preprocessing, LinearRegression())
lin_reg.fit(housing, housing_labels)
Pipeline(steps=[('columntransformer',
ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x123...
'households',
'median_income']),
('geo',
ClusterSimilarity(random_state=42),
['latitude', 'longitude']),
('cat',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='most_frequent')),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x12264b680>)])),
('linearregression', LinearRegression())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('columntransformer',
ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x123...
'households',
'median_income']),
('geo',
ClusterSimilarity(random_state=42),
['latitude', 'longitude']),
('cat',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='most_frequent')),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x12264b680>)])),
('linearregression', LinearRegression())])ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a700>,
func=<function column_ratio at 0...
['total_bedrooms', 'total_rooms', 'population',
'households', 'median_income']),
('geo', ClusterSimilarity(random_state=42),
['latitude', 'longitude']),
('cat',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='most_frequent')),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x12264b680>)])['total_bedrooms', 'total_rooms']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a700>,
func=<function column_ratio at 0x123a6b4c0>)StandardScaler()
['total_rooms', 'households']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a700>,
func=<function column_ratio at 0x123a6b4c0>)StandardScaler()
['population', 'households']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a700>,
func=<function column_ratio at 0x123a6b4c0>)StandardScaler()
['total_bedrooms', 'total_rooms', 'population', 'households', 'median_income']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out='one-to-one', func=<ufunc 'log'>)
StandardScaler()
['latitude', 'longitude']
ClusterSimilarity(random_state=42)
<sklearn.compose._column_transformer.make_column_selector object at 0x12264b680>
SimpleImputer(strategy='most_frequent')
OneHotEncoder(handle_unknown='ignore')
['housing_median_age']
SimpleImputer(strategy='median')
StandardScaler()
LinearRegression()
housing_predictions = lin_reg.predict(housing)
print(housing_predictions[:5].round(-2))
print(housing_labels[:5].values)
[ 70700. 288200. 186000. 189700. 270700.] [ 72100. 279600. 82700. 112500. 238300.]
from sklearn.metrics import mean_squared_error
lin_rmse = mean_squared_error(housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_rmse)
print(lin_rmse)
69239.95619019217
대부분 구역의 중간 주택 가격은 120,000불 에서 265,000불 사이 이다. 그러므로 예측 오차가 69,239불인 것은 매우 만족스럽지 못하다.
이는 모델이 훈련 데이터에 과소적합된 사례이다.
특성들이 충분한 정보를 제공하지 못했거나 모델이 충분히 강력하지 않다는 뜻이다.
from sklearn.tree import DecisionTreeRegressor
tree_reg = make_pipeline(preprocessing, DecisionTreeRegressor(random_state=42))
tree_reg.fit(housing, housing_labels)
Pipeline(steps=[('columntransformer',
ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x123...
('geo',
ClusterSimilarity(random_state=42),
['latitude', 'longitude']),
('cat',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='most_frequent')),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x12264b680>)])),
('decisiontreeregressor',
DecisionTreeRegressor(random_state=42))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('columntransformer',
ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x123...
('geo',
ClusterSimilarity(random_state=42),
['latitude', 'longitude']),
('cat',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='most_frequent')),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x12264b680>)])),
('decisiontreeregressor',
DecisionTreeRegressor(random_state=42))])ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a700>,
func=<function column_ratio at 0...
['total_bedrooms', 'total_rooms', 'population',
'households', 'median_income']),
('geo', ClusterSimilarity(random_state=42),
['latitude', 'longitude']),
('cat',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='most_frequent')),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x12264b680>)])['total_bedrooms', 'total_rooms']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a700>,
func=<function column_ratio at 0x123a6b4c0>)StandardScaler()
['total_rooms', 'households']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a700>,
func=<function column_ratio at 0x123a6b4c0>)StandardScaler()
['population', 'households']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a700>,
func=<function column_ratio at 0x123a6b4c0>)StandardScaler()
['total_bedrooms', 'total_rooms', 'population', 'households', 'median_income']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out='one-to-one', func=<ufunc 'log'>)
StandardScaler()
['latitude', 'longitude']
ClusterSimilarity(random_state=42)
<sklearn.compose._column_transformer.make_column_selector object at 0x12264b680>
SimpleImputer(strategy='most_frequent')
OneHotEncoder(handle_unknown='ignore')
['housing_median_age']
SimpleImputer(strategy='median')
StandardScaler()
DecisionTreeRegressor(random_state=42)
housing_predictions = tree_reg.predict(housing)
tree_rmse = mean_squared_error(housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_rmse)
print(tree_rmse)
0.0
오차가 0이지만 모델이 데이터에 심하게 과대적합되었을 가능성이 높다.
교차 검증으로 평가하기¶
K-fold cross_validation 기능을 사용할 수 있다.
훈련 세트를 fold 라 불리는 중복되지 않은 10개의 서브셋으로 랜덤으로 불할한다.
그런 다음 결정 트리 모델을 10번 훈련하고 평가하는데, 매번 다른 fold 를 선택해 평가에 사용한다.
from sklearn.model_selection import cross_val_score
tree_rmses = -cross_val_score(tree_reg, housing, housing_labels, scoring="neg_root_mean_squared_error", cv=10)
pd.Series(tree_rmses).describe()
count 10.000000 mean 67222.995977 std 3918.520742 min 58898.978399 25% 65673.581208 50% 67195.125565 75% 69494.553444 max 73180.532285 dtype: float64
평균 RMSE가 약 67,222이고 표준 편차가 약 3918이다.
이전의 RMSE가 0을 나온것은 과대적합 됐다는 의미이다.
from sklearn.ensemble import RandomForestRegressor
forest_reg = make_pipeline(preprocessing, RandomForestRegressor(random_state=42))
forest_rmses = -cross_val_score(forest_reg, housing, housing_labels, scoring="neg_root_mean_squared_error", cv=10)
pd.Series(forest_rmses).describe()
count 10.000000 mean 47196.080803 std 2518.953159 min 43480.358064 25% 45295.803304 50% 47347.433859 75% 48761.308355 max 51158.799732 dtype: float64
다른 강력한 모델을 사용하니 평균이 약 47,196이고 표준 편차가 약 2518이다.
이전 모델들 보다 훨씬 성능이 좋아보인다.
from sklearn.model_selection import GridSearchCV
full_pipeline = Pipeline([
("preprocessing", preprocessing),
("random_forest", RandomForestRegressor(random_state=42))
])
param_grid = [
{'preprocessing__geo__n_clusters' : [5, 8, 10],
'random_forest__max_features' : [4, 6, 8]},
{'preprocessing__geo__n_clusters' : [10, 15],
'random_forest__max_features' : [6, 8, 10]}
]
grid_search = GridSearchCV(full_pipeline, param_grid, cv=3, scoring="neg_root_mean_squared_error")
grid_search.fit(housing, housing_labels)
GridSearchCV(cv=3,
estimator=Pipeline(steps=[('preprocessing',
ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<f...
<sklearn.compose._column_transformer.make_column_selector object at 0x12264b680>)])),
('random_forest',
RandomForestRegressor(random_state=42))]),
param_grid=[{'preprocessing__geo__n_clusters': [5, 8, 10],
'random_forest__max_features': [4, 6, 8]},
{'preprocessing__geo__n_clusters': [10, 15],
'random_forest__max_features': [6, 8, 10]}],
scoring='neg_root_mean_squared_error')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GridSearchCV(cv=3,
estimator=Pipeline(steps=[('preprocessing',
ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<f...
<sklearn.compose._column_transformer.make_column_selector object at 0x12264b680>)])),
('random_forest',
RandomForestRegressor(random_state=42))]),
param_grid=[{'preprocessing__geo__n_clusters': [5, 8, 10],
'random_forest__max_features': [4, 6, 8]},
{'preprocessing__geo__n_clusters': [10, 15],
'random_forest__max_features': [6, 8, 10]}],
scoring='neg_root_mean_squared_error')Pipeline(steps=[('preprocessing',
ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a7...
ClusterSimilarity(n_clusters=15,
random_state=42),
['latitude', 'longitude']),
('cat',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='most_frequent')),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x1222e7830>)])),
('random_forest',
RandomForestRegressor(max_features=6, random_state=42))])ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a700>,
func=<function column_ratio at 0...
['total_bedrooms', 'total_rooms', 'population',
'households', 'median_income']),
('geo',
ClusterSimilarity(n_clusters=15,
random_state=42),
['latitude', 'longitude']),
('cat',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='most_frequent')),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x1222e7830>)])['total_bedrooms', 'total_rooms']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a700>,
func=<function column_ratio at 0x123a6b4c0>)StandardScaler()
['total_rooms', 'households']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a700>,
func=<function column_ratio at 0x123a6b4c0>)StandardScaler()
['population', 'households']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a700>,
func=<function column_ratio at 0x123a6b4c0>)StandardScaler()
['total_bedrooms', 'total_rooms', 'population', 'households', 'median_income']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out='one-to-one', func=<ufunc 'log'>)
StandardScaler()
['latitude', 'longitude']
ClusterSimilarity(n_clusters=15, random_state=42)
<sklearn.compose._column_transformer.make_column_selector object at 0x1222e7830>
SimpleImputer(strategy='most_frequent')
OneHotEncoder(handle_unknown='ignore')
['housing_median_age']
SimpleImputer(strategy='median')
StandardScaler()
RandomForestRegressor(max_features=6, random_state=42)
'preprocessing__geo__n_clusters'를 이중 밑줄 문자를 기준으로 나누고 파이프라인에서 "preprocessing"이란 이름의 추정기를 갖는다.
그러면 결국 전처리 ColumnTransformer를 찾게 된다.
그 다음 ColumnTransformer 안에서 "aeo"란 이름의 변환기를 찾는다. 그 다음 이 변환기의 n_clusters 하이퍼파라미터를 찾는다.
grid_search.best_params_
{'preprocessing__geo__n_clusters': 15, 'random_forest__max_features': 6}
cv_res = pd.DataFrame(grid_search.cv_results_)
cv_res.sort_values(by=['mean_test_score'], ascending=False, inplace=True)
cv_res.head()
| mean_fit_time | std_fit_time | mean_score_time | std_score_time | param_preprocessing__geo__n_clusters | param_random_forest__max_features | params | split0_test_score | split1_test_score | split2_test_score | mean_test_score | std_test_score | rank_test_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 12 | 3.141139 | 0.041889 | 0.079032 | 0.001094 | 15 | 6 | {'preprocessing__geo__n_clusters': 15, 'random_forest__max_features': 6} | -42841.092308 | -44286.939181 | -44953.711747 | -44027.247745 | 881.804950 | 1 |
| 6 | 2.055135 | 0.028790 | 0.077795 | 0.001111 | 10 | 4 | {'preprocessing__geo__n_clusters': 10, 'random_forest__max_features': 4} | -43584.491070 | -44459.923019 | -45406.274917 | -44483.563002 | 743.927968 | 2 |
| 13 | 4.073087 | 0.056764 | 0.080348 | 0.000618 | 15 | 8 | {'preprocessing__geo__n_clusters': 15, 'random_forest__max_features': 8} | -43665.507479 | -44474.867271 | -45582.794892 | -44574.389881 | 785.886471 | 3 |
| 7 | 2.900375 | 0.036890 | 0.078141 | 0.000772 | 10 | 6 | {'preprocessing__geo__n_clusters': 10, 'random_forest__max_features': 6} | -44112.113955 | -44873.307502 | -45890.107614 | -44958.509691 | 728.358851 | 4 |
| 9 | 2.937912 | 0.020553 | 0.081964 | 0.005904 | 10 | 6 | {'preprocessing__geo__n_clusters': 10, 'random_forest__max_features': 6} | -44112.113955 | -44873.307502 | -45890.107614 | -44958.509691 | 728.358851 | 4 |
랜덤 서치¶
하이퍼파라미터 탐색 공간이 커지면 RandomizedSearchCV가 종종 선호 된다.
그리디 서치와 같은 방식을 사용하지만 가능한 모든 조합을 시도하는 대신 각 반복마다 하이퍼파라미터에 임의의 수를 대입하여 지정한 횟수만큼 평가한다.
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs = {'preprocessing__geo__n_clusters' : randint(low=3, high=50),
'random_forest__max_features' : randint(low=2, high=20),}
rnd_search = RandomizedSearchCV(full_pipeline, param_distribs, n_iter=10, cv=3, scoring="neg_root_mean_squared_error", random_state=42)
rnd_search.fit(housing, housing_labels)
RandomizedSearchCV(cv=3,
estimator=Pipeline(steps=[('preprocessing',
ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_...
<sklearn.compose._column_transformer.make_column_selector object at 0x12264b680>)])),
('random_forest',
RandomForestRegressor(random_state=42))]),
param_distributions={'preprocessing__geo__n_clusters': <scipy.stats._distn_infrastructure.rv_discrete_frozen object at 0x122348f20>,
'random_forest__max_features': <scipy.stats._distn_infrastructure.rv_discrete_frozen object at 0x1223f4d10>},
random_state=42, scoring='neg_root_mean_squared_error')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomizedSearchCV(cv=3,
estimator=Pipeline(steps=[('preprocessing',
ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_...
<sklearn.compose._column_transformer.make_column_selector object at 0x12264b680>)])),
('random_forest',
RandomForestRegressor(random_state=42))]),
param_distributions={'preprocessing__geo__n_clusters': <scipy.stats._distn_infrastructure.rv_discrete_frozen object at 0x122348f20>,
'random_forest__max_features': <scipy.stats._distn_infrastructure.rv_discrete_frozen object at 0x1223f4d10>},
random_state=42, scoring='neg_root_mean_squared_error')Pipeline(steps=[('preprocessing',
ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a7...
ClusterSimilarity(n_clusters=45,
random_state=42),
['latitude', 'longitude']),
('cat',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='most_frequent')),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x1220b3080>)])),
('random_forest',
RandomForestRegressor(max_features=9, random_state=42))])ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a700>,
func=<function column_ratio at 0...
['total_bedrooms', 'total_rooms', 'population',
'households', 'median_income']),
('geo',
ClusterSimilarity(n_clusters=45,
random_state=42),
['latitude', 'longitude']),
('cat',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='most_frequent')),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x1220b3080>)])['total_bedrooms', 'total_rooms']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a700>,
func=<function column_ratio at 0x123a6b4c0>)StandardScaler()
['total_rooms', 'households']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a700>,
func=<function column_ratio at 0x123a6b4c0>)StandardScaler()
['population', 'households']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x123a6a700>,
func=<function column_ratio at 0x123a6b4c0>)StandardScaler()
['total_bedrooms', 'total_rooms', 'population', 'households', 'median_income']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out='one-to-one', func=<ufunc 'log'>)
StandardScaler()
['latitude', 'longitude']
ClusterSimilarity(n_clusters=45, random_state=42)
<sklearn.compose._column_transformer.make_column_selector object at 0x1220b3080>
SimpleImputer(strategy='most_frequent')
OneHotEncoder(handle_unknown='ignore')
['housing_median_age']
SimpleImputer(strategy='median')
StandardScaler()
RandomForestRegressor(max_features=9, random_state=42)
cv_res = pd.DataFrame(rnd_search.cv_results_)
cv_res.sort_values(by=['mean_test_score'], ascending=False, inplace=True)
cv_res.head()
| mean_fit_time | std_fit_time | mean_score_time | std_score_time | param_preprocessing__geo__n_clusters | param_random_forest__max_features | params | split0_test_score | split1_test_score | split2_test_score | mean_test_score | std_test_score | rank_test_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 4.942078 | 0.131189 | 0.088467 | 0.005679 | 45 | 9 | {'preprocessing__geo__n_clusters': 45, 'random_forest__max_features': 9} | -41647.442138 | -42970.861752 | -43352.626990 | -42656.976960 | 730.664808 | 1 |
| 8 | 3.831755 | 0.035142 | 0.082047 | 0.000508 | 32 | 7 | {'preprocessing__geo__n_clusters': 32, 'random_forest__max_features': 7} | -41858.401126 | -43487.709543 | -43575.195634 | -42973.768768 | 789.492321 | 2 |
| 5 | 2.495969 | 0.013436 | 0.082404 | 0.000743 | 42 | 4 | {'preprocessing__geo__n_clusters': 42, 'random_forest__max_features': 4} | -41931.467729 | -44216.304378 | -43551.069739 | -43232.947282 | 959.521079 | 3 |
| 6 | 1.845646 | 0.006965 | 0.082586 | 0.000889 | 24 | 3 | {'preprocessing__geo__n_clusters': 24, 'random_forest__max_features': 3} | -42181.257487 | -44260.876786 | -43899.375570 | -43447.169948 | 907.219764 | 4 |
| 0 | 8.095736 | 0.215393 | 0.081403 | 0.003587 | 41 | 16 | {'preprocessing__geo__n_clusters': 41, 'random_forest__max_features': 16} | -42546.555880 | -43496.910871 | -44433.805124 | -43492.423958 | 770.472810 | 5 |
최상의 모델과 오차 분석¶
정확한 예측을 만들기 위해 각 특성의 상대적인 중요도를 알려준다.
final_model = rnd_search.best_estimator_
feature_importances = final_model["random_forest"].feature_importances_
feature_importances.round(2)
array([0.07, 0.06, 0.05, 0.01, 0.01, 0.01, 0.01, 0.18, 0.01, 0.01, 0.03,
0.01, 0.01, 0.01, 0.03, 0.01, 0. , 0.01, 0.02, 0.02, 0.01, 0.02,
0. , 0.02, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.03,
0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01,
0.01, 0.01, 0.02, 0.01, 0. , 0.01, 0.01, 0.03, 0.01, 0. , 0.08,
0. , 0. , 0. , 0.01])
sorted(zip(feature_importances, final_model["preprocessing"].get_feature_names_out()))
[(np.float64(2.691595614786875e-07), 'cat__ocean_proximity_ISLAND'), (np.float64(0.00012565927491107174), 'cat__ocean_proximity_NEAR BAY'), (np.float64(0.0018236571722017115), 'cat__ocean_proximity_NEAR OCEAN'), (np.float64(0.003671813261309296), 'cat__ocean_proximity_<1H OCEAN'), (np.float64(0.0038626198281910347), 'geo__클러스터 8 유사도'), (np.float64(0.0039858606001746235), 'geo__클러스터 40 유사도'), (np.float64(0.004930124791779361), 'geo__클러스터 14 유사도'), (np.float64(0.005115789347391392), 'geo__클러스터 7 유사도'), (np.float64(0.005645260234506817), 'geo__클러스터 42 유사도'), (np.float64(0.0060023558393333745), 'log__total_bedrooms'), (np.float64(0.006047334962707391), 'log__households'), (np.float64(0.006389890782651786), 'geo__클러스터 32 유사도'), (np.float64(0.006616234811870666), 'geo__클러스터 39 유사도'), (np.float64(0.006766646232405828), 'geo__클러스터 31 유사도'), (np.float64(0.006804891399646699), 'log__total_rooms'), (np.float64(0.006907653318879322), 'log__population'), (np.float64(0.007095458493151233), 'geo__클러스터 9 유사도'), (np.float64(0.0071204448240187075), 'geo__클러스터 16 유사도'), (np.float64(0.0072129973509904195), 'geo__클러스터 35 유사도'), (np.float64(0.007429269172852502), 'geo__클러스터 27 유사도'), (np.float64(0.007764537471073966), 'geo__클러스터 3 유사도'), (np.float64(0.007775427731439553), 'geo__클러스터 19 유사도'), (np.float64(0.007935445098064438), 'geo__클러스터 34 유사도'), (np.float64(0.008636327835640325), 'geo__클러스터 12 유사도'), (np.float64(0.008775404756533836), 'geo__클러스터 37 유사도'), (np.float64(0.009081243880500828), 'geo__클러스터 23 유사도'), (np.float64(0.00916251545425963), 'geo__클러스터 22 유사도'), (np.float64(0.009293984927303194), 'geo__클러스터 29 유사도'), (np.float64(0.009422919390453331), 'geo__클러스터 20 유사도'), (np.float64(0.00951989946005952), 'geo__클러스터 44 유사도'), (np.float64(0.009540957164101454), 'geo__클러스터 21 유사도'), (np.float64(0.009613086208267434), 'geo__클러스터 18 유사도'), (np.float64(0.009735125610279982), 'geo__클러스터 4 유사도'), (np.float64(0.01053662605703823), 'geo__클러스터 41 유사도'), (np.float64(0.010745253583333132), 'geo__클러스터 5 유사도'), (np.float64(0.010887164609756438), 'remainder__housing_median_age'), (np.float64(0.011233509716453101), 'geo__클러스터 0 유사도'), (np.float64(0.011844452925928485), 'geo__클러스터 33 유사도'), (np.float64(0.012188604225881855), 'geo__클러스터 25 유사도'), (np.float64(0.012299567204974987), 'geo__클러스터 36 유사도'), (np.float64(0.012325014876450643), 'geo__클러스터 30 유사도'), (np.float64(0.012580980295056478), 'geo__클러스터 28 유사도'), (np.float64(0.013197442663651446), 'geo__클러스터 17 유사도'), (np.float64(0.01477768197713623), 'geo__클러스터 1 유사도'), (np.float64(0.01488061737953922), 'geo__클러스터 26 유사도'), (np.float64(0.015147123129185718), 'geo__클러스터 38 유사도'), (np.float64(0.016250964101274207), 'geo__클러스터 13 유사도'), (np.float64(0.017546917845922393), 'geo__클러스터 15 유사도'), (np.float64(0.018317106405257945), 'geo__클러스터 11 유사도'), (np.float64(0.022585312356443444), 'geo__클러스터 10 유사도'), (np.float64(0.02514081759708994), 'geo__클러스터 6 유사도'), (np.float64(0.025849242308343366), 'geo__클러스터 24 유사도'), (np.float64(0.02903182771769595), 'geo__클러스터 2 유사도'), (np.float64(0.0327869606575914), 'geo__클러스터 43 유사도'), (np.float64(0.0497944322875551), 'people_per_house__ratio'), (np.float64(0.05802341607038389), 'rooms_per_house__ratio'), (np.float64(0.06893621867344897), 'bedrooms__ratio'), (np.float64(0.0772785174473593), 'cat__ocean_proximity_INLAND'), (np.float64(0.17600312204073593), 'log__median_income')]
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
final_predictions = final_model.predict(X_test)
final_rmse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_rmse)
print(final_rmse)
39768.9801422105
론칭, 모니터링, 시스템 유지 보수¶
import joblib
joblib.dump(final_model, "final_model.pkl")
연습 문제¶
1.¶
from sklearn.svm import SVR
from sklearn.model_selection import GridSearchCV
pipline = Pipeline([
('preprocessing', preprocessing),
('svr', SVR())
])
param_grid = [
{'svr__kernel': ['linear'], 'svr__C' : [10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0, 80.0, 90.0, 100.0]},
{'svr__kernel' : ['rbf'], 'svr__C' : [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0], 'svr__gamma' : [0.01, 0.03, 0.1, 0.3, 1.0, 3.0]}
]
grid_search = GridSearchCV(pipline, param_grid, cv=3, scoring="neg_root_mean_squared_error",)
grid_search.fit(housing.iloc[:5000], housing_labels.iloc[:5000])
GridSearchCV(cv=3,
estimator=Pipeline(steps=[('preprocessing',
ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<f...
<sklearn.compose._column_transformer.make_column_selector object at 0x121c4fc20>)])),
('svr', SVR())]),
param_grid=[{'svr__C': [10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0,
80.0, 90.0, 100.0],
'svr__kernel': ['linear']},
{'svr__C': [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0,
9.0, 10.0],
'svr__gamma': [0.01, 0.03, 0.1, 0.3, 1.0, 3.0],
'svr__kernel': ['rbf']}],
scoring='neg_root_mean_squared_error')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GridSearchCV(cv=3,
estimator=Pipeline(steps=[('preprocessing',
ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<f...
<sklearn.compose._column_transformer.make_column_selector object at 0x121c4fc20>)])),
('svr', SVR())]),
param_grid=[{'svr__C': [10.0, 20.0, 30.0, 40.0, 50.0, 60.0, 70.0,
80.0, 90.0, 100.0],
'svr__kernel': ['linear']},
{'svr__C': [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0,
9.0, 10.0],
'svr__gamma': [0.01, 0.03, 0.1, 0.3, 1.0, 3.0],
'svr__kernel': ['rbf']}],
scoring='neg_root_mean_squared_error')Pipeline(steps=[('preprocessing',
ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e7...
'households',
'median_income']),
('geo',
ClusterSimilarity(random_state=42),
['latitude', 'longitude']),
('cat',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='most_frequent')),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x10f672090>)])),
('svr', SVR(C=100.0, kernel='linear'))])ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e700>,
func=<function column_ratio at 0...
['total_bedrooms', 'total_rooms', 'population',
'households', 'median_income']),
('geo', ClusterSimilarity(random_state=42),
['latitude', 'longitude']),
('cat',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='most_frequent')),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x10f672090>)])['total_bedrooms', 'total_rooms']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e700>,
func=<function column_ratio at 0x121c6e7a0>)StandardScaler()
['total_rooms', 'households']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e700>,
func=<function column_ratio at 0x121c6e7a0>)StandardScaler()
['population', 'households']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e700>,
func=<function column_ratio at 0x121c6e7a0>)StandardScaler()
['total_bedrooms', 'total_rooms', 'population', 'households', 'median_income']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out='one-to-one', func=<ufunc 'log'>)
StandardScaler()
['latitude', 'longitude']
ClusterSimilarity(random_state=42)
<sklearn.compose._column_transformer.make_column_selector object at 0x10f672090>
SimpleImputer(strategy='most_frequent')
OneHotEncoder(handle_unknown='ignore')
['housing_median_age']
SimpleImputer(strategy='median')
StandardScaler()
SVR(C=100.0, kernel='linear')
print(grid_search.best_params_)
print(-grid_search.best_score_)
{'svr__C': 100.0, 'svr__kernel': 'linear'}
78730.7547170174
2.¶
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import expon, loguniform
param_distribs = [
{'svr__kernel' : ['linear', 'rbf'],
'svr__C' : loguniform(20, 200_000),
'svr__gamma' : expon(scale=0.1),
}
]
rnd_search = RandomizedSearchCV(pipline, param_distribs, n_iter=10, cv=3, scoring="neg_root_mean_squared_error", random_state=42)
rnd_search.fit(housing.iloc[:5000], housing_labels.iloc[:5000])
RandomizedSearchCV(cv=3,
estimator=Pipeline(steps=[('preprocessing',
ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_...
<sklearn.compose._column_transformer.make_column_selector object at 0x121c4fc20>)])),
('svr', SVR())]),
param_distributions=[{'svr__C': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x10f5c44d0>,
'svr__gamma': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x121c7ec30>,
'svr__kernel': ['linear', 'rbf']}],
random_state=42, scoring='neg_root_mean_squared_error')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomizedSearchCV(cv=3,
estimator=Pipeline(steps=[('preprocessing',
ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_...
<sklearn.compose._column_transformer.make_column_selector object at 0x121c4fc20>)])),
('svr', SVR())]),
param_distributions=[{'svr__C': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x10f5c44d0>,
'svr__gamma': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x121c7ec30>,
'svr__kernel': ['linear', 'rbf']}],
random_state=42, scoring='neg_root_mean_squared_error')Pipeline(steps=[('preprocessing',
ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e7...
ClusterSimilarity(random_state=42),
['latitude', 'longitude']),
('cat',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='most_frequent')),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x121c7faa0>)])),
('svr',
SVR(C=np.float64(157055.10989448498),
gamma=np.float64(0.02649704000500244)))])ColumnTransformer(remainder=Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('standardscaler',
StandardScaler())]),
transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e700>,
func=<function column_ratio at 0...
['total_bedrooms', 'total_rooms', 'population',
'households', 'median_income']),
('geo', ClusterSimilarity(random_state=42),
['latitude', 'longitude']),
('cat',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='most_frequent')),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x121c7faa0>)])['total_bedrooms', 'total_rooms']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e700>,
func=<function column_ratio at 0x121c6e7a0>)StandardScaler()
['total_rooms', 'households']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e700>,
func=<function column_ratio at 0x121c6e7a0>)StandardScaler()
['population', 'households']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e700>,
func=<function column_ratio at 0x121c6e7a0>)StandardScaler()
['total_bedrooms', 'total_rooms', 'population', 'households', 'median_income']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out='one-to-one', func=<ufunc 'log'>)
StandardScaler()
['latitude', 'longitude']
ClusterSimilarity(random_state=42)
<sklearn.compose._column_transformer.make_column_selector object at 0x121c7faa0>
SimpleImputer(strategy='most_frequent')
OneHotEncoder(handle_unknown='ignore')
['housing_median_age']
SimpleImputer(strategy='median')
StandardScaler()
SVR(C=np.float64(157055.10989448498), gamma=np.float64(0.02649704000500244))
print(rnd_search.best_params_)
print(-rnd_search.best_score_)
{'svr__C': np.float64(157055.10989448498), 'svr__gamma': np.float64(0.02649704000500244), 'svr__kernel': 'rbf'}
58449.64073758919
3.¶
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
selector_pipline = Pipeline([
('preprocessing', preprocessing),
('selector', SelectFromModel(RandomForestRegressor(random_state=42), threshold=0.005)),
('svr', SVR(C=rnd_search.best_params_['svr__C'], gamma=rnd_search.best_params_['svr__gamma'], kernel=rnd_search.best_params_['svr__kernel']))
])
selector_rmses = -cross_val_score(selector_pipline, housing.iloc[:5000], housing_labels[:5000], scoring="neg_root_mean_squared_error", cv=3)
pd.Series(selector_rmses).describe()
count 3.000000 mean 58952.772839 std 4004.390718 min 54973.037842 25% 56938.473227 50% 58903.908612 75% 60942.640337 max 62981.372061 dtype: float64
4.¶
from sklearn.neighbors import KNeighborsRegressor
from sklearn.base import MetaEstimatorMixin, clone, check_is_fitted
class FeatureFromRegressor(MetaEstimatorMixin, TransformerMixin, BaseEstimator):
def __init__(self, estimator):
self.estimator = estimator
def fit(self, X, y=None):
estimator_ = clone(self.estimator)
estimator_.fit(X, y)
self.estimator_ = estimator_
self.n_features_in_ = self.estimator_.n_features_in_
if hasattr(self.estimator, 'feature_names_in_'):
self.feature_names_in_ = self.estimator.feature_names_in_
return self
def transform(self, X):
check_is_fitted(self)
predictions = self.estimator_.predict(X)
if predictions.ndim == 1:
predictions = predictions.reshape(-1, 1)
return predictions
def get_feature_names_out(self, names=None):
check_is_fitted(self)
n_outputs = getattr(self.estimator_, 'n_outputs_', 1)
estimator_class_name = self.estimator_.__class__.__name__
estimator_short_name = estimator_class_name.lower().replace('_', '')
return [f"{estimator_short_name}_prediction_{i}" for i in range(n_outputs)]
from sklearn.utils.estimator_checks import check_estimator
check_estimator(FeatureFromRegressor(KNeighborsRegressor()))
--------------------------------------------------------------------------- AssertionError Traceback (most recent call last) Cell In[61], line 2 1 from sklearn.utils.estimator_checks import check_estimator ----> 2 check_estimator(FeatureFromRegressor(KNeighborsRegressor())) File /opt/anaconda3/envs/Machine_Learning-with-Scikit-Learn-Keras-TensorFlow/lib/python3.12/site-packages/sklearn/utils/_param_validation.py:216, in validate_params.<locals>.decorator.<locals>.wrapper(*args, **kwargs) 210 try: 211 with config_context( 212 skip_parameter_validation=( 213 prefer_skip_nested_validation or global_skip_validation 214 ) 215 ): --> 216 return func(*args, **kwargs) 217 except InvalidParameterError as e: 218 # When the function is just a wrapper around an estimator, we allow 219 # the function to delegate validation to the estimator, but we replace 220 # the name of the estimator by the name of the function in the error 221 # message to avoid confusion. 222 msg = re.sub( 223 r"parameter of \w+ must be", 224 f"parameter of {func.__qualname__} must be", 225 str(e), 226 ) File /opt/anaconda3/envs/Machine_Learning-with-Scikit-Learn-Keras-TensorFlow/lib/python3.12/site-packages/sklearn/utils/estimator_checks.py:858, in check_estimator(estimator, generate_only, legacy, expected_failed_checks, on_skip, on_fail, callback) 854 test_can_fail, reason = _should_be_skipped_or_marked( 855 estimator, check, expected_failed_checks 856 ) 857 try: --> 858 check(estimator) 859 except SkipTest as e: 860 # We get here if the test raises SkipTest, which is expected in cases where 861 # the check cannot run for instance if a required dependency is not 862 # installed. 863 check_result = { 864 "estimator": estimator, 865 "check_name": _check_name(check), (...) 869 "expected_to_fail_reason": reason, 870 } File /opt/anaconda3/envs/Machine_Learning-with-Scikit-Learn-Keras-TensorFlow/lib/python3.12/site-packages/sklearn/utils/estimator_checks.py:1283, in check_estimator_sparse_tag(name, estimator_orig) 1281 except Exception as e: 1282 raise AssertionError(err_msg) from e -> 1283 raise AssertionError( 1284 f"Estimator {name} didn't fail when fitted on sparse data " 1285 "but should have according to its tag " 1286 f"self.input_tags.sparse={tags.input_tags.sparse}. " 1287 f"The tag is inconsistent and must be fixed." 1288 ) AssertionError: Estimator FeatureFromRegressor didn't fail when fitted on sparse data but should have according to its tag self.input_tags.sparse=False. The tag is inconsistent and must be fixed.
knn_reg = KNeighborsRegressor(n_neighbors=3, weights='distance')
knn_transformer = FeatureFromRegressor(KNeighborsRegressor())
geo_features = housing[["latitude", "longitude"]]
knn_transformer.fit_transform(geo_features, housing_labels)
array([[ 68920.],
[263460.],
[ 73340.],
...,
[139660.],
[213320.],
[ 60740.]])
knn_transformer.get_feature_names_out()
['kneighborsregressor_prediction_0']
from sklearn.base import clone
transformers = [(name, clone(transformer), columns) for name, transformer, columns in preprocessing.transformers]
geo_index = [name for name, _, _ in transformers].index("geo")
transformers[geo_index] = ("geo", knn_transformer, ["latitude", "longitude"])
new_geo_preprocessing = ColumnTransformer(transformers)
new_geo_preprocessing = Pipeline([
('preprocessing', new_geo_preprocessing),
('svr', SVR(C=rnd_search.best_params_["svr__C"], gamma=rnd_search.best_params_["svr__gamma"], kernel=rnd_search.best_params_["svr__kernel"]),)
])
new_pipe_rmses = -cross_val_score(new_geo_preprocessing, housing.iloc[:5000], housing_labels[:5000], scoring="neg_root_mean_squared_error", cv=3)
pd.Series(new_pipe_rmses).describe()
count 3.000000 mean 92362.869453 std 2411.855626 min 90224.461873 25% 91055.697606 50% 91886.933338 75% 93432.073243 max 94977.213148 dtype: float64
5.¶
param_distribs = {
"preprocessing__geo__estimator__n_neighbors": range(1, 30),
"preprocessing__geo__estimator__weights": ["distance", "uniform"],
"svr__C" : loguniform(20, 200_000),
"svr__gamma" : expon(scale=0.1),
}
new_geo_rnd_search = RandomizedSearchCV(new_geo_preprocessing, param_distribs, n_iter=10, cv=3, scoring="neg_root_mean_squared_error", random_state=42)
new_geo_rnd_search.fit(housing.iloc[:5000], housing_labels.iloc[:5000])
RandomizedSearchCV(cv=3,
estimator=Pipeline(steps=[('preprocessing',
ColumnTransformer(transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e700>,
func=<function column_ratio at 0x121c6e7a0>)),
('standardscaler',
StandardScaler()...
param_distributions={'preprocessing__geo__estimator__n_neighbors': range(1, 30),
'preprocessing__geo__estimator__weights': ['distance',
'uniform'],
'svr__C': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x125b3e390>,
'svr__gamma': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x125b3ffe0>},
random_state=42, scoring='neg_root_mean_squared_error')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomizedSearchCV(cv=3,
estimator=Pipeline(steps=[('preprocessing',
ColumnTransformer(transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e700>,
func=<function column_ratio at 0x121c6e7a0>)),
('standardscaler',
StandardScaler()...
param_distributions={'preprocessing__geo__estimator__n_neighbors': range(1, 30),
'preprocessing__geo__estimator__weights': ['distance',
'uniform'],
'svr__C': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x125b3e390>,
'svr__gamma': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x125b3ffe0>},
random_state=42, scoring='neg_root_mean_squared_error')Pipeline(steps=[('preprocessing',
ColumnTransformer(transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e700>,
func=<function column_ratio at 0x121c6e7a0>)),
('standardscaler',
StandardScaler())]),
['total_bedrooms',
'total_rooms...
FeatureFromRegressor(estimator=KNeighborsRegressor(n_neighbors=7)),
['latitude', 'longitude']),
('cat',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='most_frequent')),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x125c7b8f0>)])),
('svr',
SVR(C=np.float64(127024.42021281396),
gamma=np.float64(0.13167456935454494)))])ColumnTransformer(transformers=[('bedrooms',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='median')),
('functiontransformer',
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e700>,
func=<function column_ratio at 0x121c6e7a0>)),
('standardscaler',
StandardScaler())]),
['total_bedrooms', 'total_rooms']),
('rooms_per_house',
Pipeline(s...
'households', 'median_income']),
('geo',
FeatureFromRegressor(estimator=KNeighborsRegressor(n_neighbors=7)),
['latitude', 'longitude']),
('cat',
Pipeline(steps=[('simpleimputer',
SimpleImputer(strategy='most_frequent')),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x125c7b8f0>)])['total_bedrooms', 'total_rooms']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e700>,
func=<function column_ratio at 0x121c6e7a0>)StandardScaler()
['total_rooms', 'households']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e700>,
func=<function column_ratio at 0x121c6e7a0>)StandardScaler()
['population', 'households']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out=<function ratio_name at 0x121c6e700>,
func=<function column_ratio at 0x121c6e7a0>)StandardScaler()
['total_bedrooms', 'total_rooms', 'population', 'households', 'median_income']
SimpleImputer(strategy='median')
FunctionTransformer(feature_names_out='one-to-one', func=<ufunc 'log'>)
StandardScaler()
['latitude', 'longitude']
KNeighborsRegressor(n_neighbors=7)
KNeighborsRegressor(n_neighbors=7)
<sklearn.compose._column_transformer.make_column_selector object at 0x125c7b8f0>
SimpleImputer(strategy='most_frequent')
OneHotEncoder(handle_unknown='ignore')
SVR(C=np.float64(127024.42021281396), gamma=np.float64(0.13167456935454494))
-new_geo_rnd_search.best_score_
np.float64(98283.00349637523)
6.¶
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.utils.validation import check_array, check_is_fitted
class StandardScalerClone(BaseEstimator, TransformerMixin):
def __init__(self, with_mean=True):
self.with_mean = with_mean
def fit(self, X, y=None):
X_orig = X
X = check_array(X)
self.mean_ = X.mean(axis=0)
self.scale_ = X.std(axis=0)
self.n_features_in_ = X.shape[1]
if hasattr(X_orig, 'columns'):
self.feature_names_in_ = np.array(X_orig.columns, dtype=object)
return self
def transform(self, X):
check_is_fitted(self)
X = check_array(X)
if self.n_features_in_ != X.shape[1]:
raise ValueError("error features")
if self.with_mean:
X = X - self.mean_
return X / self.scale_
def inverse_transform(self, X):
check_is_fitted(self)
X = check_array(X)
if self.n_features_in_ != X.shape[1]:
raise ValueError("error features")
X = X * self.scale_
return X + self.mean_ if self.with_mean else X
def get_feature_names_out(self, input_features=None):
if input_features is None:
return getattr(self, "feature_names_in_", [f"x{i}" for i in range(self.n_features_in_)])
else:
if len(input_features) != self.n_features_in_:
raise ValueError("error features")
if hasattr(self, "feature_names_in_") and not np.all(self.feature_names_in_ == input_features):
raise ValueError("input_features != feature_names_in_")
return input_features
from sklearn.utils.estimator_checks import check_estimator
check_estimator(StandardScalerClone())
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) File /opt/anaconda3/envs/Machine_Learning-with-Scikit-Learn-Keras-TensorFlow/lib/python3.12/site-packages/sklearn/utils/estimator_checks.py:4501, in check_n_features_in_after_fitting(name, estimator_orig) 4498 with raises( 4499 ValueError, match=msg, err_msg=err_msg.format(name=name, method=method) 4500 ): -> 4501 callable_method(X_bad) 4503 # partial_fit will check in the second call File /opt/anaconda3/envs/Machine_Learning-with-Scikit-Learn-Keras-TensorFlow/lib/python3.12/site-packages/sklearn/utils/_set_output.py:319, in _wrap_method_output.<locals>.wrapped(self, X, *args, **kwargs) 317 @wraps(f) 318 def wrapped(self, X, *args, **kwargs): --> 319 data_to_wrap = f(self, X, *args, **kwargs) 320 if isinstance(data_to_wrap, tuple): 321 # only wrap the first output for cross decomposition Cell In[88], line 22, in StandardScalerClone.transform(self, X) 21 if self.n_features_in_ != X.shape[1]: ---> 22 raise ValueError("error features") 23 if self.with_mean: ValueError: error features The above exception was the direct cause of the following exception: AssertionError Traceback (most recent call last) Cell In[89], line 2 1 from sklearn.utils.estimator_checks import check_estimator ----> 2 check_estimator(StandardScalerClone()) File /opt/anaconda3/envs/Machine_Learning-with-Scikit-Learn-Keras-TensorFlow/lib/python3.12/site-packages/sklearn/utils/_param_validation.py:216, in validate_params.<locals>.decorator.<locals>.wrapper(*args, **kwargs) 210 try: 211 with config_context( 212 skip_parameter_validation=( 213 prefer_skip_nested_validation or global_skip_validation 214 ) 215 ): --> 216 return func(*args, **kwargs) 217 except InvalidParameterError as e: 218 # When the function is just a wrapper around an estimator, we allow 219 # the function to delegate validation to the estimator, but we replace 220 # the name of the estimator by the name of the function in the error 221 # message to avoid confusion. 222 msg = re.sub( 223 r"parameter of \w+ must be", 224 f"parameter of {func.__qualname__} must be", 225 str(e), 226 ) File /opt/anaconda3/envs/Machine_Learning-with-Scikit-Learn-Keras-TensorFlow/lib/python3.12/site-packages/sklearn/utils/estimator_checks.py:858, in check_estimator(estimator, generate_only, legacy, expected_failed_checks, on_skip, on_fail, callback) 854 test_can_fail, reason = _should_be_skipped_or_marked( 855 estimator, check, expected_failed_checks 856 ) 857 try: --> 858 check(estimator) 859 except SkipTest as e: 860 # We get here if the test raises SkipTest, which is expected in cases where 861 # the check cannot run for instance if a required dependency is not 862 # installed. 863 check_result = { 864 "estimator": estimator, 865 "check_name": _check_name(check), (...) 869 "expected_to_fail_reason": reason, 870 } File /opt/anaconda3/envs/Machine_Learning-with-Scikit-Learn-Keras-TensorFlow/lib/python3.12/site-packages/sklearn/utils/_testing.py:147, in _IgnoreWarnings.__call__.<locals>.wrapper(*args, **kwargs) 145 with warnings.catch_warnings(): 146 warnings.simplefilter("ignore", self.category) --> 147 return fn(*args, **kwargs) File /opt/anaconda3/envs/Machine_Learning-with-Scikit-Learn-Keras-TensorFlow/lib/python3.12/site-packages/sklearn/utils/estimator_checks.py:4498, in check_n_features_in_after_fitting(name, estimator_orig) 4495 if method == "score": 4496 callable_method = partial(callable_method, y=y) -> 4498 with raises( 4499 ValueError, match=msg, err_msg=err_msg.format(name=name, method=method) 4500 ): 4501 callable_method(X_bad) 4503 # partial_fit will check in the second call File /opt/anaconda3/envs/Machine_Learning-with-Scikit-Learn-Keras-TensorFlow/lib/python3.12/site-packages/sklearn/utils/_testing.py:1114, in _Raises.__exit__(self, exc_type, exc_value, _) 1109 err_msg = self.err_msg or ( 1110 "The error message should contain one of the following " 1111 "patterns:\n{}\nGot {}".format("\n".join(self.matches), str(exc_value)) 1112 ) 1113 if not any(re.search(match, str(exc_value)) for match in self.matches): -> 1114 raise AssertionError(err_msg) from exc_value 1115 self.raised_and_matched = True 1117 return True AssertionError: `StandardScalerClone.transform()` does not check for consistency between input number of features with StandardScalerClone.fit(), via the `n_features_in_` attribute. You might want to use `sklearn.utils.validation.validate_data` instead of `check_array` in `StandardScalerClone.fit()` and StandardScalerClone.transform()`. This can be done like the following: from sklearn.utils.validation import validate_data ... class MyEstimator(BaseEstimator): ... def fit(self, X, y): X, y = validate_data(self, X, y, ...) ... return self ... def transform(self, X): X = validate_data(self, X, ..., reset=False) ... return X
np.random.seed(42)
X = np.random.rand(1000, 3)
scaler = StandardScalerClone()
X_scaled = scaler.fit_transform(X)
assert np.allclose(X_scaled, (X - X.mean(axis=0)) / X.std(axis=0))
scaler = StandardScalerClone()
X_back = scaler.inverse_transform(scaler.fit_transform(X))
assert np.allclose(X, X_back)
assert np.all(scaler.get_feature_names_out() == ["x0", "x1", "x2"])
df = pd.DataFrame({"a" : np.random.rand(100), "b": np.random.randn(100)})
scaler = StandardScalerClone()
X_scaled = scaler.fit_transform(df)
assert np.all(scaler.feature_names_in_ == ["a", "b"])
assert np.all(scaler.get_feature_names_out() == ["a", "b"])
이 내용은 [Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow]책을 참조하고 있습니다.¶
'Data science > 머신러닝' 카테고리의 다른 글
| Classification (0) | 2025.03.30 |
|---|---|
| Machine Learning란? (0) | 2025.03.16 |
| PCA(주성분 분석) (3) | 2022.07.23 |
| K-means clustering(k-평균 알고리즘) (0) | 2022.07.23 |
| Loss function(손실 함수) (0) | 2022.07.17 |

